对于爬虫来说,主要的任务就是获取页面的内容,从最初页面直接后端渲染结果后输出到后端输出模版再使用ajax等技术来渲染数据,而随着前端技术的发展,越来越多的网站开始使用纯js来渲染页面,比如Vue、React等。
而对于爬虫来说,想要获取页面内容,也从最初的直接拿到页面内容,变成了针对不同页面针对性写爬取规则,比如A页面,有3个ajax用来获取渲染数据,那么就要对于爬取A页面的爬虫,就要再写3个针对ajax的数据爬取
而当需要爬取的页面越来越多的时候,如何能提升效率呢?
于是,针对页面的解析工作,就交给了一些浏览器核去处理了,Phantomjs就是一个基于webkit的js api,能够实现浏览器的功能,这样我们将一个页面输入给Phantomjs,其就如同一个浏览器一样,去解析执行这个页面,获取最终展示的结果。
这两种方式各有优缺点:
- 针对页面写特定爬虫,准确,执行效率快,维护性差,一旦页面接口变动则需要根据变动修改爬虫
- Phantomjs通用性高,不需要针对特定页面去写,但执行速度慢(相当于浏览器访问页面了,其所有网络访问都渲染完成了才结束)
那么如何使用Phantomjs呢?
首先是环境,其官网为http://phantomjs.org
推荐使用docker来pull一个镜像,环境都配好了,省事,我使用的是 wernight/phantomjs 这个镜像
下面我们来写个测试页面:
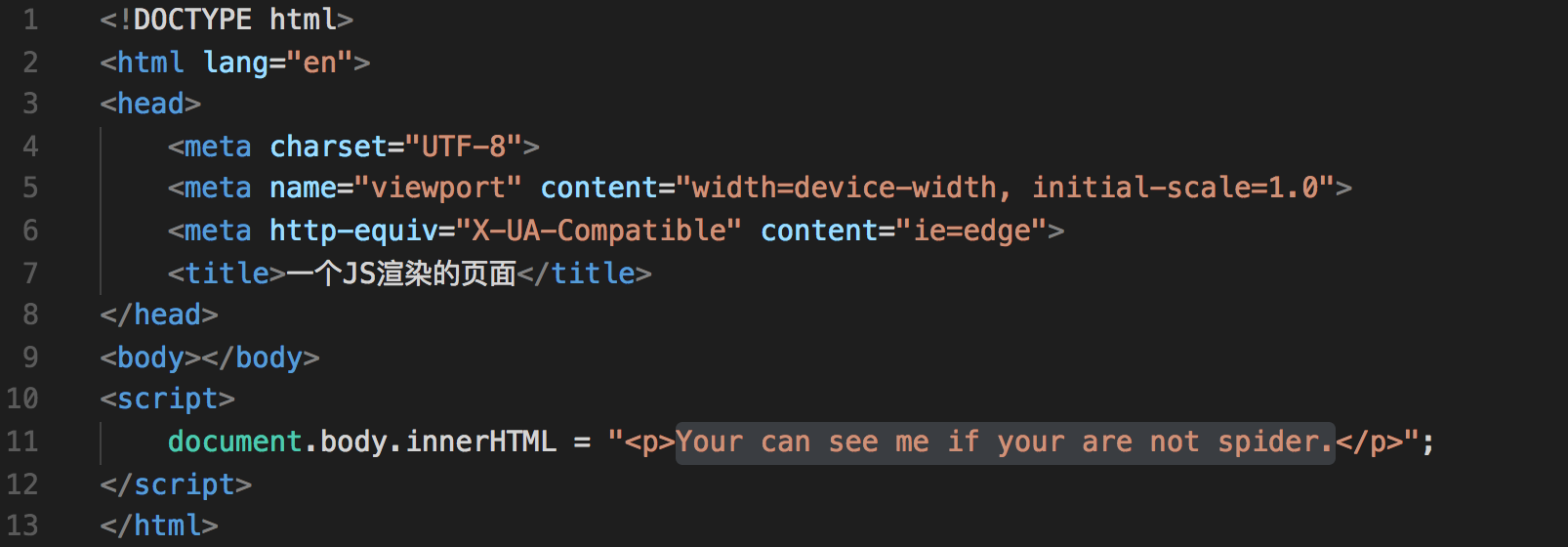
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>一个JS渲染的页面</title>
</head>
<body></body>
<script>
document.body.innerHTML = "<p>Your can see me if your are not spider.</p>";
</script>
</html>很简单的一个页面,其会在页面生成一句 Your can see me if your are not spider.
而这句话是通过js来写出的,也就是说,如果你使用传统方式,拿到的body内容是空的
测试如下
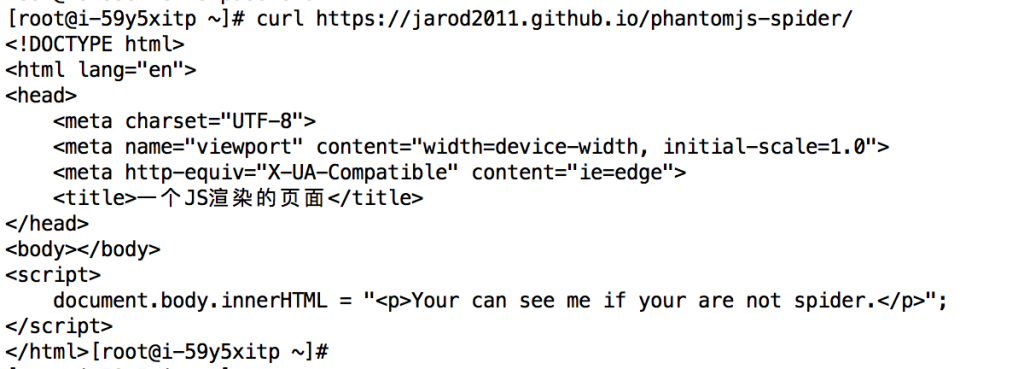
可以看到,使用curl获取地址后,页面的body里内容是空的
下面我们来写一个测试脚本,在Phantomjs中去执行
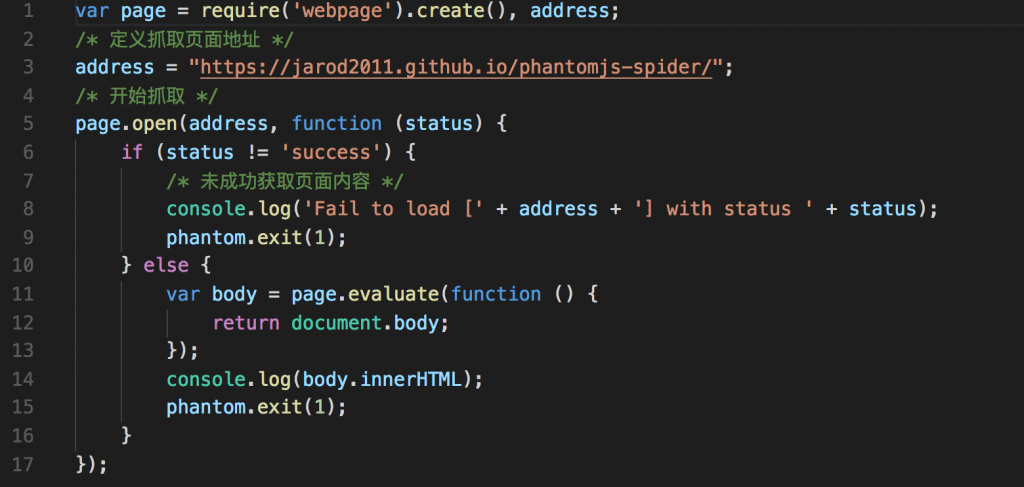
var page = require('webpage').create(), address;
/* 定义抓取页面地址 */
address = "https://jarod2011.github.io/phantomjs-spider/";
/* 开始抓取 */
page.open(address, function (status) {
if (status != 'success') {
/* 未成功获取页面内容 */
console.log('Fail to load [' + address + '] with status ' + status);
phantom.exit(1);
} else {
var body = page.evaluate(function () {
return document.body;
});
console.log(body.innerHTML);
phantom.exit(1);
}
});在Phantomjs环境中执行:

我们可以看到,其解析了js,并将最终渲染页面拿到了。
今天就到这里,后面针对Phantomjs还有很多用法,包括在拿到页面中执行方法,引入其他页面脚本等我都会后续更新。